
Les structures de données et la complexité algorithmique : comment mesurons nous l’efficatité de notre logiciel? une histoire du “Grand O” (Big O) ou O(n) Partie 2 : L’importance des algorithmes.
Quel est l’importance des algorithmes en developpement logiciel?
Dans le chapitre precedent, on a essayé de donner une idée de ce que sont les structures de données et l’approche qu’on utilise pour le calcule de l’efficacité des operations qu’on peut faire sur une structure de données quelconque en particulier les vecteurs. Nous abordons dans ce chapitre la notion d’algorithme en informatique: au fait qu’est ce qu’un algorithme?
Un algorithme c’est un ensemble d’instruction necessaire pour accomplir une tache donnée.Dans le cas d’un ordinateur, le bout de code que nous en tant que developpeur écrivons et le faisons executer l’ordinateur constitue en fait un algorithme, par exemple dans le chapitre précedent, on a utilise deux algorithmes differents pour imprimer à l’écran les nombres paires compris entre 0 et 100. Pour mieux expliquer cette notion d’algorithme prenons l’exemple suivant:
Un vecteur Ordonné
un vecteur ordonné est un vecteur donc la particularité reside dans le fait qu’il contient uniquement des valeurs ordonnés par exemple s’il s’agit d’un vecteur de nombres, ces nombres doivent etre ordonnés du plus petit au plus grand ou s’il s’agit un vecteur de chaine de caracteres comme le vecteur des regions dans le chapitre precedent, les valeurs dpoivent etre ordonnés par ordre alphabetique. A chaque insertion dans un vecteur ordonné, la valeur à inserer doit etre place dans une position ou le vecteur doit rester toujours ordonné, prenons l’exemple du vecteur ordonné suivant:

supposons qu’on veuille inserer la valeur “20” dans ce vecteur, dans le cas d’un vecteur simple (non ordonné) il suffira de le mettre juste à la fin

et comme on l’a vu au chapitre precedent, l’ordinateur fait ce type d’insertion en seulement une seule étape, mais dans le cas d’un vecteur ordoné cela n’est pas du tout possible car il faut l’inserer absolument à sa juste position

et comem vous pouvez l’imaginer, l’ordinateur pour faire ce type d’insertion doit effectuer une serie de recherche pour confronter les éléments du vecteur afin de savoir si leur valeur est plus grand ou plus petit par rapport au chiffre “20” et c’est seulement une fois avoir fait une recherche correcte qu’il sera à mesure de trouver la position ou inserer cette valeur. Voyons en image comment l’ordinateur devra faire pour inserer le nombre “20” à sa juste position dans ce vecteur:

L’ordinateur commencera par l’index 0 qui contient la valeur 5, comme 5 est plus petit que 20, l’ordinateur sait qu’il ne peut pas inserer le chiffre 20 a gauche de 5 mais à sa droite, avant de chercher à l’inserer à sa droite, il va d’abord lire le contenu de l’élement qui se trouve à la droite de l’index 0 donc l’index 1 et il decouvre que c’est le chiffre 15, comme 15 est inferieur à 20,

l’ordinateur va successivement se deplacer à la droite de l’index 1 et faire une “confrontation” avec la valeur 45

Comme 45 est plus grand que 20, “Bingo” l’ordinateur à présent sait qu’il va inserer le chiffre à la gauche de 45 et donc à la droite de 15, pour le faire il doit deplacer tous les elements à la droite de 15, l’image suivante explique tout le processus, en “1” il deplace 99 dans une cellule vide, puis en “2” il deplace 77 et en “3” 45 pour faire de la place à 20. On peut donc imaginer le nombre d’étapes utiliser pour faire cette opération

Si on fait la meme chose sur un vecteur de N élement on peut donc conconclure que pour faire une insertion de ce genre il faut N+2 étapes que l’on doit inserer la valeur au debut ou à la fin ou au milieu on aura pratiquement le meme nombre d’étapes, le meilleur cas c’est si on veut inserer une valeur qui est plus grande à la fin du vecteur dans ce cas on aura au moins N+1 étapes à faire.Donc en terme d’opération d’insertion, un vecteur ordonné est moins efficace qu’in simple vecteur non ordonné, cependant nous allons voir que pour une opération de recherche linéaire, il y a beaucoup d’avantage dans un vecteur ordonné:
Recherche dans un vecteur ordonné: dans un vecteur non ordonné, pour faire une recherche linéaire on doit parcourir tous les éléments du vecteur et faire une comparaison, supposons que dans l’exemple précédent on veut chercher une valeur qui n’existe pas dans le vecteur par exemple le nombre “17”, dans un vecteur simple, il faudra parcourir tous les élements pour constater à la fin que ce nombre n’existe pas dans le vecteur, mais dans le cas d’un vecteur ordonné, la recherche s’arrete à peine on trouve un nombre plus grand de “17” car le vecteur étant ordonné, il est inutile d’aller faire des comparaisons sur des éléments qu’on sait d’office qu’ils sont plus grand de “17”. Ci dessous observons un bout de code en language c# qui fait une recherche linéaire sur un vecteur ordonné:
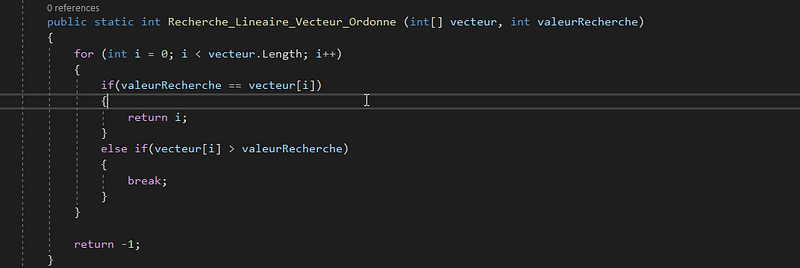
La recherche linéaire en fait c’est un algorithme ou on parcourt tous les éléments d’un vecteur à la recherche d’une valeur prédefinie et nous venons de voir comment on peut écrire un bout de code pour son implementation, cependant la recherche linéaire n’est pas le seul algorithme utilisé pour effectuer une recherche dans un vecteur, voyons en d’autre type d’algorithme de recherche:
La Recherche Binéaire: Il vous est souvent arrivé de jouer à ce fameux jeux avec votre ami qui consiste à :”Penser à un nombre et lui il doit le deviner, s’il ne trouve pas le nombre vous lui dite si ce que vous avez pensé est plus grand ou plus petit et il en propose un autre jusqu’à trouver le nombre magique”, dans ce petit jeux, votre ami fait une chose simple, à chaque fois qu’il propose un nombre pas exacte et que vous l’orienter en disant que ce nombre est plus grand ou plus petit par rapport au nombre magique, il divise la recherche par deux, la recherche bineaire fonctione de la meme manière. Supposons que dans notre vecteur precedent:

nous voulons utilisée la recherche binéaire pour trouver le nombre 45 dans ce vecteur, l’algorithme procède comme suit:
L’algorithme commence sa recherche au centre du vecteur :

Comme la valeur au centre du vecteur est 99, l’algorithme conclut que cette valeur est superieur à la valeur recherchée 45 par consequence, il va éliminer toutes les valeurs à la gauche de 99 (il ne va plus explorer de ce coté pour faire la recherche)

l’algorithme va ensuite se positioner au centre des éléments resta à savoir à l’index contenant la valeur 15, comme 15 est inferieur à la valeur recherchée(45), il va faire la meme chose que precedement en éliminant de sa zone de recherche tout ce qui se trouve à la gauche de 15 y compris 15,

A ce moment precis il ne reste plus que deux éléments dans la recherche, l’algorithme va continuer dans sa meme logique, à savoir se positioner au milieu des éléments du vecteur restant, cette fois ci ça sera exactement sur 45

Il faut tout de suite remarque que la recherche bineaire n’est possible qu’avec un vecteur ordonné, dans le cas d’un vecteur non ordonné cela n’est pas possible, donc l’un des avantages d’un vecteur ordonné est qu’on peut facilement effectuer une recherche binéaire et donc faire moins d’étapes.
Voici ci dessous un bout de code en language c# qui implemente l’algorithme de la recherche binéaire:
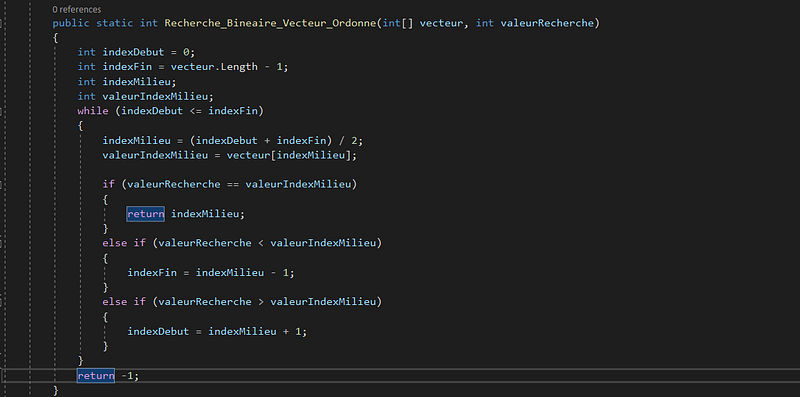
Passons à présent à une confrontation entre l’algorithme de recherche linéaire et binéaire. Avec un vecteur d’une petite dimention, les deux algorithmes en terme d’efficacité ne sont pas absolument differents, cependant avec un vecteur d’une taille importante, il y a une difference considerable. Prenons le cas d’un vecteur contenenant 100 éléments, l’algorithme de recherche linéaire fera 100 étapes alors que le binéaire n’en fera que 7 étapes car si la valeur que nous recherchons se retrouve dans la dernière cellule on sera contraint de parcourir tous les élements du vecteur pour retrouver l’élement recherché alors que dans le cas d’une recherche binéaire, à chaque étape on élimine la moitié des éléments à rechercher, dejà dès la première itération, on élimine 50 élements, on peut conclure que pour un vecteur de seulement 3 éléments, la recherche binéaire fera au maximum 2 étapes, si on double le nombre d’élément dans le vecteur et on passe par exemple à 7 éléments, on fera au maximum 3 étapes, si nous doublons de nouveau et passons de 7 éléments à 15 éléments(le nombre impaire est laissé casuellement pour que l’algorithme se positionne toujours au milieu), le nombre d’étapes sera 4, donc à chaque fois qu’on double la taille du vecteur, la recherche binéaire augmente d’une seule étape comparativement à la recherche linéaire. On peut representer cette tendance entre les deux algoritmes dans un repère orthonorme de la manière suivante:
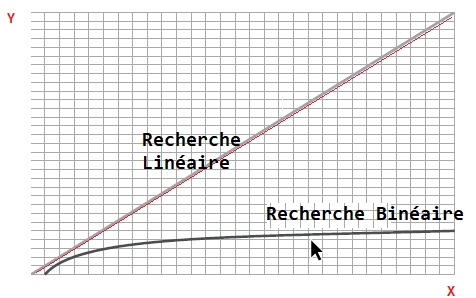
Comme on peut l’apprehender sur ce graphe, il y a une constante croissante de la recherche linéaire alors que la recherche binéaire au fur et à mesure qu’augmente le nombre d’élément du vecteur devient presque constant.
Comme on peut bien l’avoir compris, les vecteurs ordonnés sont moins efficaces en terme d’insertion comparativement aux vecteurs non ordonnés, mais dans le cas d’une recherche ce type de structure de données est beaucoup plus efficace comme par exemple avec une recherche binéaire, donc quand nous voulons ecrire un code efficace, il faut toujours choisir la structure de données qui correspond le mieux à la problematique que l’on veut resoudre et surtout y appliquer l’algoritme qui nous permettra d’effectuer la tache requis avec moins d’etapes, d’ou la notion de “Grand O” qui sera l’objet du prochain chapitre.
Exercise:
1. Combien d’étapes peuvent mettre successivement une recherche linéaire et binéaire dans un vecteur de 2500 élements?
2. Combien d’étape mettra les algorithmes de recherche linéaire et binéaire pour retrouver le nombre 11 dans le vecteur A=[1,3,5,6,9,11,45,78,89,300,345,678,900]

Subscribe to ITInnovDesign's newsletter to receive the latest news and exclusive offers.

12.08.2022, 17:03
Comments: 0

12.08.2022, 17:04
Comments: 0

17.08.2022, 22:01
Comments: 0

31.08.2022, 17:12
Comments: 0
Bienvenue sur ITInnov-Design, l'espace des informaticiens, l'espace du codage, le lieu par excellence ou on essaye d'expliquer les choses complexes de manière Simple et surtout Terre à Terre pour permettre à tous ceux qui veulent s'avventurer dans le monde de l'informatique et du coding de ne pas etre frustré et d'entrer par la grande porte. Tous nos postes sont vos préoccupations et tout commentaires de votre part peut etre l'objet d'un autre post pour mieux eduquer, mieux approffondire et du coup n'hesitez pas à faire des questions, des remarques des suggestions dans tous nos canaux de communication de manière qu'on puisse aborder beaucoup de sujet meme de manière repetitives car, on peut expliquer la meme chose plusieurs fois de plusieurs manières differentes: en Informatqiuey, Qui Maitrise mieux son Sujet doit pouvoir l'expliquer de manière simple à un débutant Ou à une persone qui est nouveau ou ignorant sur le sujet c'est notre objectif.

Orvilledop Guest
15.05.2024, 16:04
Post: Comment fonctionnent Internement les guichets automatiques ?
Franck Guest
14.05.2024, 19:34
Post: Comment deployer un site web statique sur github?
Franck Guest
14.05.2024, 19:29
Post: Comment deployer un site web statique sur github?
Orvilledop Guest
11.05.2024, 03:21
Post: Comment fonctionnent Internement les guichets automatiques ?