
Les structures de données et la complexité algorithmique : comment mesurons nous l’efficatité de notre logiciel? une histoire du “Grand O” (Big O) ou O(n)
Je propose dans une serie d’articles, des extraits de mon livre pour les classes de 4ème et 3ème qui portent exclusivement sur la notion de structure de données et la complexité algorithmique dans le monde du developpement des logiciels, dans ces extraits, j’expliques pour les nuls comment on peut juger de l’efficacité d’un algorithme et comment choisir une structure de donnée idoine quand on veut resoudre un probleme specifique en phase de developpement de logiciel.
Quand on affronte le monde du developpement des logiciels pour la première fois, notre objectif premier est de savoir si notre logiciel fonctionne et rien de plus, mais plus on acquiert de l’experience et qu’on devienne un architect de logiciel, on commence à apprendre autres caracteristiques du logiciel surtout sa qualité, par exemple savoir que deux bouts de code écrit pour resoudre le meme problème mais de manière differente, quel soit le plus bien en terme de performance.
prenons cet exemple simple de ce bout de code (snippet code) écris en language c#

lequel de ces deux fontions est plus rapide en terme d’execution? onpeut tout de suite dire que la deuxième version sera plus rapide dans la mesure ou la version 1 fera 100 iterations alors que la version 2 n’en fera que la moitie.
L’objectif d’un bon developpeur de logiciel est celui d’ecrire du “bon code”: c’est à dire du code qui, non seulement est structuré, mais s’excute de manière rapide et efficace.
Qu’est ce qu’une structure de donnée? au fait que sont les données?
Les données en informatique surtout dans le jargon du developpement de logiciel signifit de manière generale tout type d’information que peut traiter un ordinateur en commençant par les objets fondamentaux que sont les nombres et les chianes de caracteres. Une structure de donnée est donc la manière donc ces données sont organisées. Voyons à présent comment on peut organiser les données de plusieurs manières.
Connaitre comment sont organisées les données est fondamentale dans le developpement d’un logiciel.
les vecteurs (Array) : c’est la première structure de données qu’on doit connaitre, c’est la manière de stocker facilement un ensemble de données qu’on veut par la suite manipuler, par exemple si on veut creer un programe qui affiche la liste des 10 regions du cameroun dans un menu deroulant, il est très facile et beaucoup intuitif de creer un vecteur qui le contient et de le mettre comme source de données pour le menu deroulant, en c# on écrira le code ci dessous:

Les vecteurs ont leur propre jargon: la dimension(size) indique le nombre d’élément que contient le vecteur dans le cas de notre exemple ci dessus 10,l’indice(index) qui specifie exactement la position ddu vecteur ou il y a une information particulière, dans de nombreux language de programmation, l’indice commence toujours par “0”:

Pour mieux comprendre la performance des structures de données tel que les vecteurs, il faut bien connaitre comment le code que nous écrivons interagit avec ses structures de données. Les operations que le developpeur fait généralement avec les structures de données sont:
Lecture: dans cette opération il s’agit de recuperer une donnée dans une position particulière de la structure de données, dans le cas des vecteurs, il s’agit d’une donnée particulière dans un index quelconque, par exemple trouver quelle region se trouve en index6 de l’array(vecteur) dans notre exemple ce qui correspond à la chaine de caractère “Nord ouest”.
Recherche :dans ce type d’opération, on doit parcourir la structure de données pour retrouver un élement ayant une valeur particulière, pour les vecteurs par exemple, il s’agit de dire si une valeur donnée se trouve ou non dans le vecteur par exemple la chaine de caractère “extreme sud ” se trouve t’elle dans notre vecteur?
Insertion: cette operation comme son nom peut indiquer, consiste à inserer une nouvelle donnée(valeur) dans la structure, dans le cas d’un vecteur, il s’agit simplement d’inserer une valeur dans une position donnée du vecteur, par exemple inserer “extreme sud ” en position 5.
Elimination : éliminer une valeur dans une structure revient à enlever completement de la structure une valeur qui se trouve dans une position donnée.
Comment mesure t’on l’efficacité ou mieux la vitesse de chaque opération?
Attention, par vitesse, on entend par là non pas le temps mis pour faire l’opération, mais le nombre d’étape utiliser pour cette operation particulière.Tout au début de ce chapitre, on a choisit la deuxième version d’imprimer les nombres paires pas pour le temps d’exécution mais pour le nombre d’itération(étapes) utiliser par cette méthode pour imprimer les nombres à savoir la moitié de la première version.Pourquoi ne pouvons pas mesurer l’efficacite d’une opération en terme du temps d’execution? pour la simple raison que le meme bout de code peut prendre moins de temps à s’executer dans une machine, mais met plus de temps dans une autre, tout depend du materiel(hardware) ou devra etre executer le code, donc mesurer la vitesse d’exécution se basant sur son temps mis n’est pas ideale parceque le temps est variable selon le materiel ou devra s’executer le code en question.
Cependant on peut mesurer la vitesse d’execution d’un programme en terme du nombre d’étape utilisé pour executer le programme, par exemple si nous avons deux bout de code pour faire la meme opération, le bout de code A qui prend 10 étapes, et le bout de code B qui en prend 100 étapes pour accomplir le meme problem, alors il est intuitif de dire que le bout de code A sera plus efficace et plus rapide que le bout de code B quelque soit le materiel sur lequel devra s’executer ce code.
Opération de lecture : un ordinateur peut lire dans un vecteur juste en une seule étape, dans l’exemple du vecteur avec les 10 regions du cameroun, si nous reguardons quelque chose disons à l’index 6, l’ordinateur le fera en une seule étape et nous rapportera la valeur “Nord ouest”, comment cela est il possible?
La mémoire d’un ordinateur est organisé comme une grille (c’est juste une vision simplifiée de la mémoire d’un ordinateur dans l’unique optique de mieux faire comprendre la dèmarche)
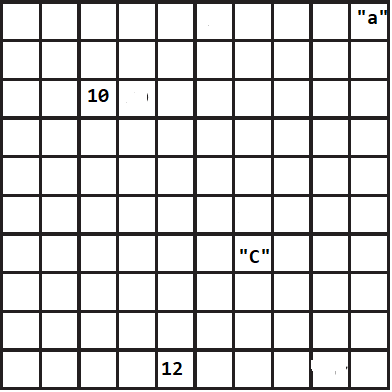
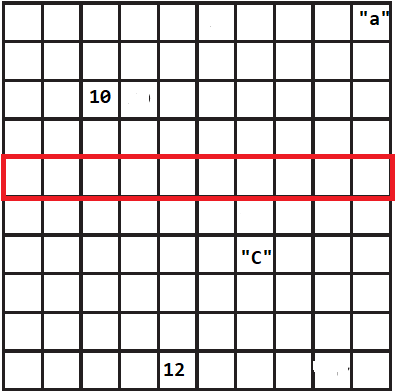
Quand nous déclarons un vecteur comme nous l’avons fait pour les région du cameroun en language c#, l’ordinateur cherche dans sa mémoire une zone contigue vide qui peut conténir exactement le nombre d’élément présent dans notre vecteur, par exemple il pourra choisir la zone en rouge sur l’image suivant:
Pour identifier les données contenues dans la mémoire, chaque cellule de la mémoire contient une addresse, c’est à dire un numero unique qui permet à l’ordinateur d’identifier son contenu, les addresse on des numeros progressifs d’une cellule à l’autre

Notre vecteur de 10 regions si on se refère à cette organisation pourra ainsi etre placé comme suit dans la mémoire de l’ordinateur:

Pour une opération de lecture, l’ordinateur va directement à l’index qui contient la valeur car :
Si nous demandons à l’oridinatuer de nous restituer la valeur conenue à l’index 4 par exemple, il le fera toujours en une etape, car il connait l’addresse de l’index 1 de notre vecteur et comme les addresses sont des suites contigues et progressive, il suffit pour lui de sommer l’addresse du premier index plus 4 et il aura l’adresse à l’index 4 et donc en une étape il peut pointer et lire le contenu qui se trouve à cette addresse. Dans le cas de notre exemple, l’ordinateur a noté quelque part que notre vecteur commence à l’addresse 540, quand nous lui demandons que nous voulons obetenir le contenu de l’index 4, il fait une simple opération 540 +4 et obtient 544 et nous retourne la valeur “Nord”. On peut donc conclure que l’opération de lecture d’un vecteur pour un ordinateur est une opération rapide et efficace.Toute opération qui necessite d’une seule étape est generalement dit efficace.
Opération de recherche: dans une opération de lecture, nous donnons un index à l’orinateur et il nous retourne le contenue de la valeur à l’addresse de cet index, dans une operation de recherche on a exactement le contraire, à savoir nous donnons une valeur à l’ordinateur et on lui demande de nous dire à quel index elle se trouve, ces deux opérations bien que similaire dans un premier temps sont differentes en terme d’efficacité.L’operation de lecture est rapide dans la mesure ou l’ordinateur peut aller en une seule etape à la bonne addresse, alors que dans l’operation de recherche, l’ordinateur ne connait pas l’index, il doit donc parcourir le vecteur à la recherche de la valeur et retrouver l’index, l’ordinateur ne connait pas ce qui se trouve dans le contenu d’une addresse, pour lui c’est une boite noire, il connait juste l’addresse. Supposons que dans notre vecteur on veuille chercher la chaine de caractère “Nord”, l’ordinateur commencera par l’index 0 et effectuera une lecture de son contenu et le confronte à “Nord”, comme on peut le voir le premier index contient “centre”, donc ce n’est pas le bon resultat, il devra donc se depalcer à l’index suivant et faire la meme opération:

Dans le cas de cette recherche, comme l’ordinateur utilise 5 étapes pour trouver la chaine de caractère on dira que l’opération prend 4 étapes, ce type d’opération de recherche est une opération dite linéaire (linear search en anglais), posons nous la question à present de savoir quel est le nombre d’opération maximale que peut faire l’ordinateur pour effectuer une recherche linéaire dans un vecteur? Si la valeur recherchée se retrouve dans la dernière cellule du vecteur comme c’est le cas de “Adamaoua” dans notre exemple, l’ordinateur devra parcourir tout le vecteur et lire cellule par cellule,cela va de meme si la valeur recherchée ne se trouve pas dans le vecteur, l’ordinateur devra de toutes les façons parcourir tout le vecteur, on peut donc dire que pour un vecteur de 10 éléments, une recherche linéaire se fera au maximum en 10 étape, et pour un vecteur de 100 éléments il se fera en 100 étapes ainsi de suite,pour le generaliser, nous pouvons dire que pour un vecteur de N élements, une recherche linéaire utilisera au maximum N étapes. Dans tous les cas, une opération de lecture est plus efficace qu’une opération de recherche dans la simple mésure ouelle necessite moins d’étapes.
Opération d’insertion: l’efficacité dans une opération depend de la position ou on veut inserer la donnée,par exemple si on veut inserer une valeur comme dernier élement du vecteur, cela se fera en une seule étape car l’ordinateur, outre à memoriser l’adresse de l’index du premier élement du vecteur lors de l’allocation de la mémoire, memorise aussi la dimention du vecteur, comme on peut l’imaginer, il suffit de prendre l’addresse du premier element et d’y ajouter la dimension du vecteur pour savoir l’adresse du dernier élément ainsi inserer de manière simple la valeur, il n’aura donc pas besoin de parcourir tout le vecteur, cependant si nous voulons inserer une valeur au debut ou au milieu du vecteur, la chose devient compliquer, il faudra deplacer certains éléments dans le vecteur pour faire place à cette nouvelle valeur, jettons un coup d’oeil attentif à la figure suivante:

supposons que l’on veuille inserer la chaine “Extreme sud” en index 2, comme on peut bien l’imaginer, l’ordinateur va commencer par deplacer “Adamaoua” dans la zone “vide”, ensuite “Est” à l’adresse ou il y avait “Adamaoua”, puis “Extreme nord” ou il y avait “Est” ainsi de suite jusqu’à faire de la place à “Extreme sud” en position 2.On peut donc dire que cette opération necessite de 9 étapes pour etre accomplie, le cas le plus “mauvais” ou cette operation necessite de plusieurs etapes est quand nous inserons un élément au debut du vecteur, dans ce cas il faut deplacer tous les élements du vecteur vers la droite.Conclusion, pour un vecteur de N éléments, le cas le plus mauvais se fera en N+1 étapes.
Opération d’élimination: Dans une telle opération, comme on peut l’immaginer il faut faire le vide, c’est vrai faire du vide necessite d’une seule étape, cependant, un vecteur dans la memoire d’un ordinateur est une suite contigue comme nous l’avons vu, donc il ne peut avoir du vide entre deux élément d’un vecteur, du coup l’ordinateur devra deplacer les élements à droites de l’element qu’on veut éliminer pour les confluer vers la gauche

Dans l’image ci dessus, si on veut eliminer la region du sud, il faudra deplacer de la droite vers la gauche en position 2, successivement, “OUEST”, puis “LITTORALE” ensuite “NORD” etc.. le cas le “plus mauvais” c’est quand on veut éliminer le premier élement du vecteur exactement comem dans le cas de l’insertion, dans ce cas il faudra deplacer tout le reste des éléments vers la gauche, dans ce cas, pour un vecteur de 100 éléments, il faut une étape pour eliminer l’element plus 99 étape pour deplacer tous les élements restant de la droite vers la gauche, on peut donc generaliser en disant que pour N élément il faut au maximum N ètapes dans une operation d’élimination.
Nous venons là d’examiner la complexité en temps de notre tout premier structure de données à savoir un vecteur.
Si maintenant nous prenons une autre structure de données qu’on appelle en anglais “set”, il en existe une en language c# qui s’appelle “HashSet”, il s’agit toujours d’un vecteur, mais ce type de vecteur n’admet pas de doublons donc on aura jamais dans ce vecteur deux ou plusieurs cellules qui ont un meme contenu (qui continnent la meme valeur), dans un simple vecteur on peut avoir le meme contenu dans tout le vecteur. Ce type de structure peut etre par exemple utilisée pour stocker les numeros de telephone ou de contact, dans ce cas spécifique, en tant que developpeur, on ne voudrait pas qu’il y ait de doublons avec plusieurs contacts ayant les memes numeros. Dans une telle structure, les opérations de lecture et de recherche sont identiques a celles qu’on retrouve dans un vecteur normale en terme de complexité temporelle, cependant pour l’insertion il y a une nette difference, prenons l’exemple du meilleur cas d’insertion dans un vecteur à savoir inserer une valeur comme dernier élément du vecteur , nous avons vu que avec un vecteur, cela se fait en une seule étape, cependant avec un “set”, cela n’est pas possible car le set doit verifier si l’element qu’on veut inserer n’existe pas dejà dans le vecteur, pour le faire il faut absolument une opération de recherche, en conclusion, inserer dans un set revient à faire également une recherche d’ou la necessité de plusieurs étapes dans un set comparativement à un simple vecteur (on aura exactement N+1 etapes dans le cas de l’insertion comme dernier element du vecteur, dans le cas de l’insertion au debut du vecteur il faudra 2N+1 car il faudra faire d’abord la recherche, puis deplacer tous les élement vers la droite et ensuite inserer la nouvelle valeur).
Avec cette toute petite analogie, il est donc maintenant possible de comprendre petit à petit comment il est important de comprendre la complexité d’execution du bout de code que nous écrivons en tant que developpeur informatique et surtout le choix des structures de données qui convient le mieux pour le problème qu’on veut resoudre, dans le prochain chapitre on parlera plus en profondeur de la notion d’algorithme informatique.

Subscribe to ITInnovDesign's newsletter to receive the latest news and exclusive offers.

12.08.2022, 17:03
Comments: 0

12.08.2022, 17:04
Comments: 0

17.08.2022, 22:01
Comments: 0

31.08.2022, 17:12
Comments: 0
Bienvenue sur ITInnov-Design, l'espace des informaticiens, l'espace du codage, le lieu par excellence ou on essaye d'expliquer les choses complexes de manière Simple et surtout Terre à Terre pour permettre à tous ceux qui veulent s'avventurer dans le monde de l'informatique et du coding de ne pas etre frustré et d'entrer par la grande porte. Tous nos postes sont vos préoccupations et tout commentaires de votre part peut etre l'objet d'un autre post pour mieux eduquer, mieux approffondire et du coup n'hesitez pas à faire des questions, des remarques des suggestions dans tous nos canaux de communication de manière qu'on puisse aborder beaucoup de sujet meme de manière repetitives car, on peut expliquer la meme chose plusieurs fois de plusieurs manières differentes: en Informatqiuey, Qui Maitrise mieux son Sujet doit pouvoir l'expliquer de manière simple à un débutant Ou à une persone qui est nouveau ou ignorant sur le sujet c'est notre objectif.

Orvilledop Guest
15.05.2024, 16:04
Post: Comment fonctionnent Internement les guichets automatiques ?
Franck Guest
14.05.2024, 19:34
Post: Comment deployer un site web statique sur github?
Franck Guest
14.05.2024, 19:29
Post: Comment deployer un site web statique sur github?
Orvilledop Guest
11.05.2024, 03:21
Post: Comment fonctionnent Internement les guichets automatiques ?